RAG-OpenAI-Chats: Tu Historial Completo de ChatGPT, Privado y Consultable con IA
Transforma tus exportaciones de OpenAI en una base de conocimiento local, privada y consultable mediante técnicas de Retrieval Augmented Generation (RAG).
Las conversaciones con modelos de lenguaje contienen información valiosa que suele perderse con el tiempo. Este proyecto permite convertir tu historial de ChatGPT en una base de conocimiento privada y consultable mediante RAG (Retrieval Augmented Generation).
Recuperando el Control de Tus Datos de IA #
Nota sobre la privacidad: Esta herramienta funciona 100% localmente. Tus datos nunca salen de tu ordenador a menos que decidas usar un LLM externo para el componente de generación. Incluso en ese caso, solo se envían las consultas y contextos recuperados, no todo tu historial.
RAG-OpenAI-Chats te permite tomar el control total de tu historial de conversaciones de ChatGPT. Transforma tus exportaciones de OpenAI en una base de conocimiento local, privada y consultable mediante técnicas de Retrieval Augmented Generation (RAG). ¡Pregúntale a tu "yo del pasado" sin regalar tus datos!
Motivación y Propósito del Proyecto #
Nuestras conversaciones con LLMs contienen ideas valiosas, fragmentos de código, decisiones y conocimiento acumulado. Este proyecto nace de la necesidad de:
- Recuperar el control sobre esta información, evitando que sea monetizada por terceros.
- Crear una "memoria aumentada" personal, permitiendo encontrar fácilmente información específica de chats pasados.
- Reutilizar eficientemente código y soluciones previas.
- Hacer todo esto de forma 100% local y privada por defecto.
Tecnologías y Herramientas Clave #
La implementación de este sistema utiliza un stack tecnológico moderno centrado en Python:
- Procesamiento de Datos: Pandas (para manipulación de datos exportados).
- Formato de Almacenamiento: Apache Parquet (eficiente, columnar).
- Embeddings: Sentence Transformers (para vectorización semántica).
- Base de Datos Vectorial: Milvus (indexación y búsqueda eficiente).
- Framework RAG: Haystack (para orquestar el pipeline).
- Entorno de Trabajo: Jupyter Notebooks (guía paso a paso).
- LLM para Generación: Opcional, integrable con modelos locales o APIs.
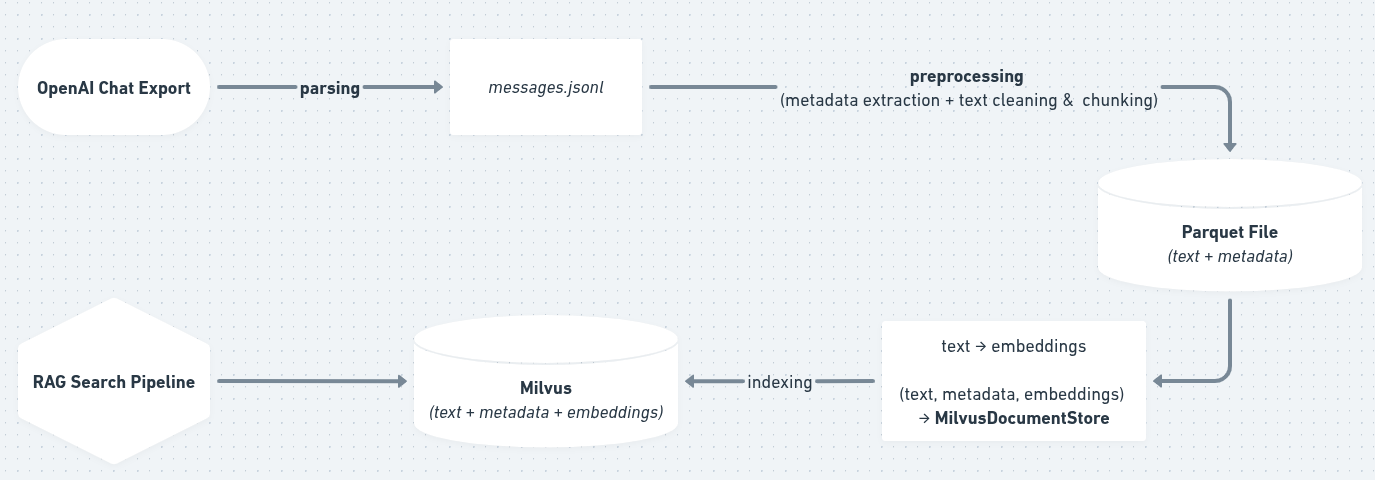
Pipeline Completo de Ingesta y Consulta #
El sistema implementa un flujo de trabajo completo para procesar y consultar tu historial:
- Exportación y Transformación: Guía para exportar chats de OpenAI y scripts/notebooks para procesarlos a formato Parquet.
- Generación de Embeddings: Uso de Sentence Transformers para convertir fragmentos de chat en vectores.
- Indexación Vectorial: Almacenamiento y creación de índices en Milvus para búsqueda semántica rápida.
- Consulta Inteligente: Implementación de un pipeline RAG con Haystack para hacer preguntas en lenguaje natural sobre tu historial.
Además, el proyecto ofrece:
- Enfoque en la Privacidad: Diseñado para funcionar localmente, con
.gitignoreconfigurado para no versionar datos sensibles. - Modularidad y Reusabilidad: El pipeline es reentrante (puede reanudarse) y permite sustituir componentes.
- Guía Paso a Paso: Notebooks de Jupyter (
01-parse-openai.ipynba04-simple-rag.ipynb) que detallan cada etapa. - CLI en desarrollo: Para una ejecución más automatizada de algunas partes.
Diagrama del Pipeline: Puedes ver una representación visual del pipeline completo en este enlace.
{kind=link}
Preguntas Frecuentes #
¿Por qué usar una base de datos vectorial en lugar de búsqueda de texto?
Las bases de datos vectoriales permiten búsquedas semánticas que capturan el significado, no solo las palabras exactas. Esto significa que puedes encontrar información relevante incluso cuando las consultas usan términos diferentes a los originales.
¿Necesito usar OpenAI para la parte de generación?
No. Puedes usar cualquier LLM, incluyendo modelos locales como Llama, Mistral u Orca Mini. El proyecto está diseñado para ser modular, permitiéndote elegir el componente de generación que prefieras.
¿Cuánta memoria/recursos consume este sistema?
Depende principalmente del tamaño de tu historial y del modelo de embeddings que elijas. Para historiales pequeños-medianos (<1000 chats), un ordenador moderno con 16GB de RAM debería ser suficiente. La base de datos Milvus puede configurarse para usar menos recursos si es necesario.
Comenzando con el Proyecto #
- Clona el repositorio:
git clone https://github.com/Intrinsical-AI/rag-openai-chats.git - Crea un entorno virtual e instala dependencias:
pip install -r requirements.txt - Exporta tus chats de OpenAI y colócalos en
data/raw/OPENAI/. - Sigue los Jupyter Notebooks en la carpeta
notebooks/para procesar tus datos y empezar a consultar.
Aprendizajes y Contribuciones #
- Una demostración práctica de cómo construir un sistema RAG completo y funcional de forma local.
- Aplicación de bases de datos vectoriales (Milvus) y modelos de embeddings (Sentence Transformers) para búsqueda semántica en datos no estructurados (conversaciones).
- Profundización en el uso de Haystack para construir pipelines de NLP complejos.
- Una solución valiosa para cualquiera que quiera aprovechar al máximo su historial de LLMs manteniendo la privacidad.
Estado Actual y Roadmap #
Actualmente funcional para OpenAI. El roadmap incluye:
- Interfaz de chat con Streamlit.
- Soporte para otros proveedores (Claude, Gemini).
- Retrieval híbrido (BM25 + Embeddings).
Enlaces:
Artículos relacionados
AI Safety: Un Problema de Lenguaje
¿Nos engañamos a nosotros mismos con términos como 'alineamiento' o 'control'? Reflexión sobre los desafíos y límites de la seguridad en IA.
Desmitificando el Mecanismo de Atención en LLMs
Una explicación accesible —pero rigurosa— del mecanismo de atención, la pieza clave tras el éxito de los modelos de lenguaje modernos.